THE EFFECTS OF RELATIVE HUMIDITY ON SOME PHYSICAL PROPERTIES OF MODERN VELLUM:ERIC F. HANSEN, STEVE N. LEE, & HARRY SOBEL
ABSTRACT—The effects of different relative humidities on some physical properties of three types of calfskin parchment (vellum) were investigated. Standard samples were subjected to (1) tensile fracture, and (2) measurement of the force that developed when the restrained samples were subjected to step decreases in relative humidity in the region between 60% and 11%. The results indicate that although no particular level of relative humidity can be excluded in general from consideration as a storage or display condition on the basis of tensile testing data alone, at 11% RH there is an adverse effect on some individual tensile properties. Relative humidities above 40% increase gelation and opportunities for biological growth. About 25% RH is the lowest level that can be tolerated without inducing large stresses in the material. On full consideration of these results, the physical chemistry and chemical reactivity of collagen, and the results of a recent study of the biodeterioration of parchment, a relative humidity of 30% seems optimum for such objects. At 30% RH, a cyclic variation of � 5% can be permitted with minimal effects of swelling and shrinkage. 1 INTRODUCTIONThis article is a discussion of the factors to be considered in determining an optimum level of relative humidity for the display and storage of parchment and other skin artifacts, based upon both a consideration of the physical chemistry and chemical reactivity of collagen and upon physical tests of modern vellum over a range of relative humidities. The Charters of Freedom of the United States (the Constitution and Declaration of Independence) and the Dead Sea Scrolls will be used as examples for this discussion. Indeed, the arguments presented for the optimum level of relative humidity for display and storage, 30% RH, do not differ significantly from those proposed by the National Bureau of Standards for the Charters of Freedom in 1951 (NBS 1951). The effects of light and concentrations of air pollutants on the deterioration of collagen, although important factors that are in all probability also dependent upon the concentration of oxygen and atmospheric moisture, are not included in the scope of this discussion. In a review of storage conditions for archives and libraries, Wilson (1986) noted that conditions for parchment and vellum could not be discussed in as concise a way as for leather and paper because systematic data on the physical properties of parchment and the degradation rates of parchment over a wide range of relative humidities were not available. In an effort to alleviate this situation, data were acquired and are reported here for the following physical properties of three types of modern vellum over a range of relative humidities from 11% to 60%:
2 BACKGROUNDThere are three primary concerns in the preservation of objects containing the protein collagen. The first is the immediate or short-term effects of the environment, primarily associated with temperature and relative humidity, on the physical properties such as strength, flexibility, permeability, and dimensional changes. The second is the long-term effects of the environment, associated with temperature, relative humidity, oxygen concentration, chemical pollutants, and radiant energy (light), in causing “aging,” or chemical modifications of the original material. Also important is how the environment allows biodeterioration by microorganisms and fungi of such a rich nutrient source. The most commonly encountered recommendations in the conservation literature for the storage and display of parchment are in the region of 50% RH to 65% RH. However, recommendations vary and include unspecified levels such as “complete dryness” for the display of parchment and vellum: “The emphasis must be toward complete dryness with no excessive changes in temperature and humidity” (Bloodworth and Parkinson 1988, 65). A recent review of the deterioration of skin in museum collections concludes, “Understanding of the complexities in preserved whole skin does not yet allow for adequate specification of ‘ideal’ conditions that will prevent deterioration” (Horie 1990, 109). The discussion of an “ideal” condition of relative humidity presented in this article is a general one relating to a broad class of objects containing collagen as a principal component (such as parchment documents) and for which the conservation aim is the long-term preservation of the collagen. It is presented with the understanding that there may also be other aims (relating either to aesthetic considerations or some use-related function of a skin artifact) or other considerations (including the environmental requirements of other component materials of a composite object or the effects of additives) that must be considered in arriving at an “optimum” concentration of atmospheric moisture. 2.1 SOME PROPERTIES OF PARCHMENTParchment and leather are both processed from the skin of animals; “vellum” is a designation for parchment made from the skin of young or unborn calfs. The history, techniques of manufacture, and properties of parchment have been extensively reviewed by Reed (1975). In general, animal skins for both parchment and leather are dehaired through soaking in baths of various compositions and scraping of hair from the surface. At this stage, parchment manufacture differs from leather manufacture. The unique properties of parchment are due to drying the wet skin under tension; the tension causes an alignment of the three-dimensional fiber network of the skin in a configuration more parallel to the surface of the skin. In contrast, the properties of leather are due to joining of the fiber network by chemical links introduced through tanning agents. The “leathered” skin excludes water from the fibers and is firmer and stronger as a result of tanning. Parchment, then, has a more aligned structure than leather, which has a complex, highly randomized weave structure. Differences resulting from the two different processes, as noted by Reed (1975) are that:
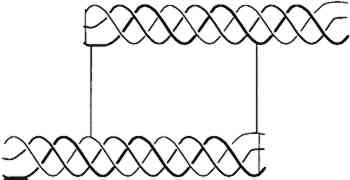
2.2 EFFECT OF ATMOSPHERIC OXYGEN AND WATER ON COLLAGENBecause parchment is processed from the skin of animals, its major constituent is insoluble collagen (which constitutes about 95% of defatted, dehaired skin, the percentage depending upon the age and sex of the animal). Therefore, the chemistry and structural stability of collagen at different levels of water content and resulting from different levels of relative humidity need to be considered. As collagen ages, in vivo or in vitro, atmospheric oxygen plays a role in its chemical modification (Sobel and Hansen 1989), Oxidation will change the molecular structure of the proteins, causing cross-linking or chemical modifications of several amino acids over time. Changes in parchment resulting from oxidation might also be influenced by the amount of residual fats and the type and amount of additives (such as softening agents) in historic parchment. Water affects collagen in several different ways. It plays a direct role in the chemical modification of collagen through hydrolysis, solvation of free radicals, hydrogen bond stability, and the rate of gelatin formation. Collagen is composed of three similar strands of a protein containing in greatest amount glycine, alanine, proline, and hydroxyproline. The spatial configurations of repeated triple amino acid sequences involving glycine, alanine, and hydroxyproline or proline are responsible for the helical conformation between the strands. A triple strand of the protein is entwined in an alpha helix termed tropocollagen, shown in figure 1. Water molecules are intimately connected with the hydrogen bonding holding the triple helix together.
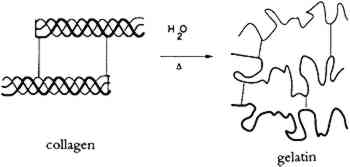
It is well known (Bull 1944; Dole and McLaren 1947) that water relates to collagen in four different processes, depending upon the vapor pressure (relative humidity), as shown in table 1. A definite amount of water is necessary for the molecular stability of the tropocollagen structure; this role for water is demonstrable in TABLE 1 TYPES OF BOUND WATER ASSOCIATED WITH COLLAGEN AT DIFFERENT RELATIVE HUMIDITIES The tensile properties of collagen are a function of moisture content. Water sorption is also intimately involved in dimensional changes (swelling) and the permeability of the material. 2.3 GELATINIZATION OF COLLAGENIn addition to chain-breaking of a macro-molecule by hydrolysis resulting in a decrease in molecular weight, another mode of protein degradation can occur through denaturation. In the case of collagen, this denaturation occurs by interaction with water and is designated gelatinization (fig 2). By heating collagen in water, the water molecules can gain sufficient energy to compete for the hydrogen bonds maintaining the triple helix configuration.
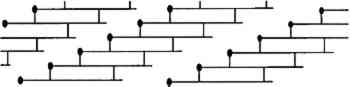
The rate of denaturation depends to some extent upon the intactness of the collagen fibrils that make up the fibers in skin. The tropocollagen molecules are cross-linked, end to end, and bundled together to form fibrils in the arrangement shown in figure 3. In skin, these fibrils form fibers that, in a three-dimensional array, are the primary component of skin. When the fibrillar structure is disturbed, as when the fibers are mechanically broken, collagen is more susceptible to attack by bacteria (Rebricova and Solovyova 1987).
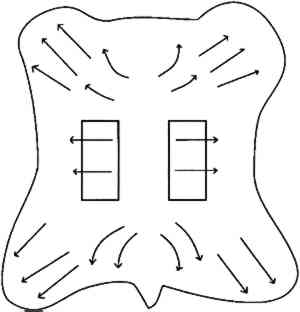
Bowes and Raistrick (1967) studied the effect of relative humidity and pH upon the extent of hydrolytic breakdown of collagen and glutaraldehyde-tanned collagen by determining the release of N-terminal residues. At 40�C for 8 weeks, hydrolysis increased for both collagen and tanned collagen with increasing humidity (in the range from 40% to 100%) and decreasing pH (in the range from 5 to 2.5). They concluded that when hydrolytic breakdown becomes extensive, denaturation follows and in turn accelerates further hydrolytic action. Measuring the effect of temperature on the deterioration of collagen is hampered because temperatures at or above the shrinkage temperature may give unreliable results (Bowes and Raistrick 1964). Of particular interest is whether physically or chemically deteriorated collagen will deteriorate at a faster rate, but this has not been demonstrated and is a matter for further study. What is known is that denaturation of disrupted collagen is promoted by less extreme conditions than those that initiate denaturation in intact collagen. The physical and chemical integrity of collagen can be indicated by the hydrothermal stability, as shown by a decrease in the shrinkage temperature for deteriorated fibrils (Young 1990). 3 EXPERIMENTAL3.1 MATERIALSAs previously discussed, the distinct properties of parchment are a result of the production process, which includes drying under tension. Some “parchment” sold today is not true parchment but a formaldehyde-tanned skin. Commercial parchment may be true parchment but may include additives and softening agents. The parchment used in this study was purchased from a vendor of true parchment. The general procedure for making parchment has been previously described (Vorst 1986). The three types of vellum (parchment made from young calf) purchased were labeled, for convenience, as “modern,” “medieval,” and “talmudic.” These designations do not indicate that the tensile properties of the vellum designated “medieval” compare with the tensile properties of parchment manufactured during the Middle Ages, but rather that a particular aspect of the production process was in common with the medieval practice of parchment making. Thus, the vellum labeled “medieval” was more fully neutralized with rinsing and soaking in comparison to the vellum designated “modern.” The vellum designated “talmudic” was, in addition to being neutralized fully with ammonium chloride, also subjected to a bath that contained small amounts of oak gall. The designation “talmudic” was chosen because the ancient Jewish method for the production of parchment either included a tanning agent in a bath or the surface was subsequently finished with a tanning agent, as shown by analysis of Dead Sea Scroll samples (Poole and Reed 1962). 3.2 SAMPLE CUTTING AND CONDITIONINGThe test samples were cut from selected areas of the whole skin as depicted in figure 4, in an attempt to obtain samples with maximum similarity in the direction of the collagen fiber bundles. Dogbone-shaped samples were cut in accordance with the American Society for Testing and Materials test method (ASTM 1984). However, due to the size of the tensile testing equipment, the sample dimensions were scaled down by a factor of 2, reducing the testing width from 12.5 mm to 6.3 mm. The thickness of the talmudic-type vellum samples was 0.2 � 0.01 mm, of the medieval-type vellum samples was 0.2 � 0.03 mm, and the modern-type vellum was 0.23 � 0.03 mm.
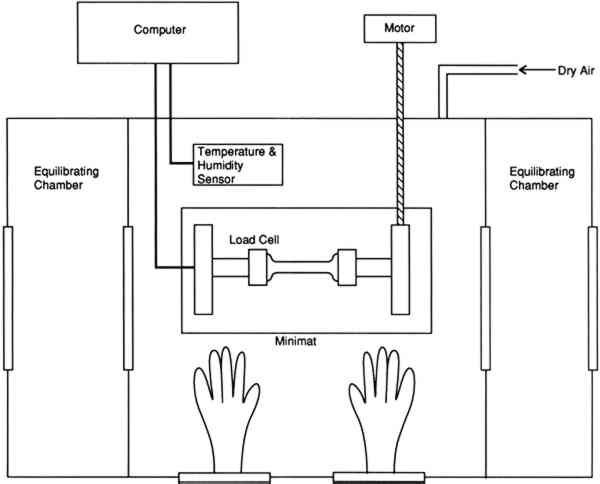
All dogbone-shaped samples were preconditioned in excess of three months prior to testing in a humidity chamber at 43%, 33%, 22%, or 11% RH, maintained by saturated salt solutions of potassium carbonate, magnesium chloride, potassium acetate, or lithium chloride, respectively. These salt solutions were chosen for their vapor pressure, which results in the desired 3.3 TENSILE PROPERTIESTensile testing and the measurement of the stress in restrained samples were performed on a Polymer Laboratories Minimat tensile testing instrument placed inside a microenvironment chamber built at the Getty Conservation Institute (fig. 5). It was necessary to have a chamber with interlocking side chambers so that samples and salt solutions could be introduced wihtout exposing the central chamber to the ambient relative humidity of the room, which is 60% RH. The vellum samples sorb water very quickly when exposed to an increased level of relative humidity.
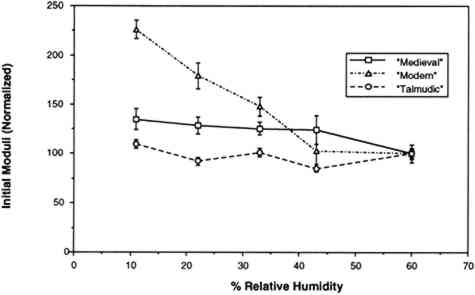
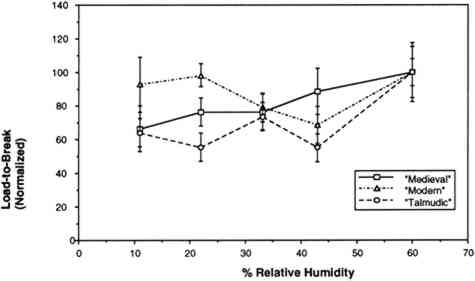
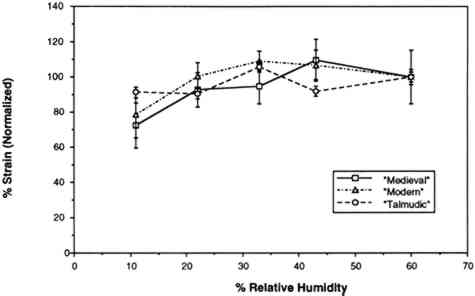
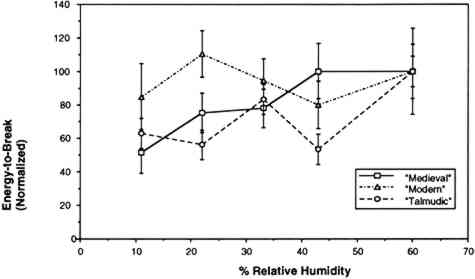
The humidity in the chamber during testing was maintained with the same saturated salt solutions used for conditioning the samples. The gauge length was 0.050 m, and the constant rate of extension was 0.020 m per minute. Ten replicate samples of each of the three vellum skins were tested on the Minimat at each relative humidity. (These 10 samples were randomized to include samples from opposite sides of the skin in each set.) Test data were recorded on an IBM AT computer with a data acquisition program that utilizes an external I/O board that converts analog signals to digital signals. Temperature and humidity were simultaneously recorded on the computer using a General Eastern Humidity and Temperature Sensor. Collected data were saved for further analysis on the Apple MacIntosh FXII computer using Stat View and Cricket Graph software. Because of the more convenient use of a larger tensile testing instrument, tensile fracture for the samples conditioned at 60% RH was performed with an Instron Model 4201 Universal Testing Instrument in the same temperature- and humidity-controlled room. Tensile test data 3.4 FORCE DEVELOPING AT A FIXED GAUGE LENGTHFor the humidity downramping tests (successive exposure to lower levels of relative humidity), straight-edged, 0.0127 m wide samples were cut with a Thwing Albert precision sample cutter from the same areas of the skins as for tensile testing. The gauge length was 0.050 m, and the samples were held at a 2 N preload in the clamps of the tensile tester. The chamber and the sample were then allowed to equilibrate at an initial relative humidity of 60%. After equilibration, the humidity was lowered to 43% by an influx of dry air, and then this humidity was maintained with the appropriate saturated salt solution while the sample was allowed to equilibrate. (The relative humidity was decreased in a stepwise manner, rather than having the humidity reduced by equilibration with the specific salt solutions.) The chamber conditions and the developing tension were monitored with a General Eastern Temperature and Humidity Transmitter and the Minimat, respectively. Data from both instruments were recorded using an IBM AT computer and an I/O board. Data were collected at 5-minute intervals for a duration of several days; the required time was dependent on the rate at which equilibration was achieved at 43%, 33%, 22%, and 11% RH. Equilibration was assumed when the force that developed held constant for 24 hours. Each type of parchment was subjected to this procedure. 4 RESULTS AND DISCUSSION4.1 RESULTS OF TENSILE TESTINGThe properties of the vellum used in this testing should reflect those of vellum that has not been treated with softening agents or other additives. The initial modulus, load-to-break, percent strain-to-break, and energy-to-break (tensile energy absorption) obtained from tensile fracture after equilibration at different relative humidities are tabulated in tables 2, 3, 4, and 5, respectively. The same properties, with standard error values used for error bars and normalized to a value of 100 for a tensile property of each type of vellum at 60% RH, are shown in figures 6, 7, 8, and 9. The tensile properties were normalized to more clearly illustrate a comparison of the relative change for each type of vellum. (As the response of the humidity sensor is not linear below 20% RH, the recorded value was 15% over a saturated lithium chloride solution. Since the recognized RH of a saturated lithium chloride solution is 11%, this value is used in the charts and graphs.) TABLE 2 INITIAL MODULUS OF THREE VELLUM TYPES AT DIFFERENT RELATIVE HUMIDITIES TABLE 3 LOAD-TO-BREAK OF THREE VELLUM TYPES AT DIFFERENT RELATIVE HUMIDITIES TABLE 4 % STRAIN-TO-BREAK OF THREE VELLUM TYPES AT DIFFERENT RELATIVE HUMIDITIES TABLE 5 ENERGY-TO-BREAK OF THREE VELLUM TYPES AT DIFFERENT RELATIVE HUMIDITIES
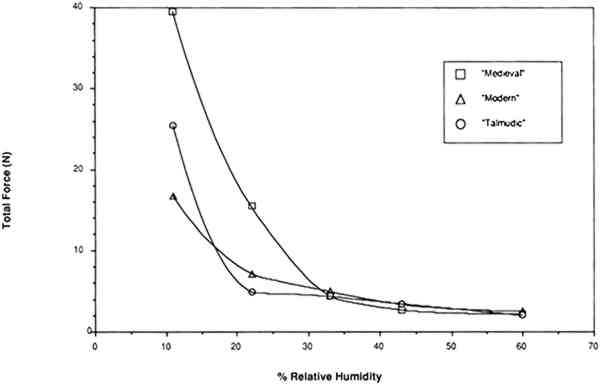
The initial modulus determined for the modern-type vellum is increased to the greatest extent as a result of equilibration at lower relative humidities, with the medieval-type vellum showing a similar trend. The value of the initial modulus for the talmudic-type parchment is relatively unaffected. The effect of changes in relative humidity on the load-to-break mean obtained after equilibration and fracture is greatest for the medievaltype vellum, with a reduction in the load-to-break mean for each reduction in RH over the range from 60% to 11%, and with the value at the lowest RH significantly different from the value at the highest RH. In contrast, the talmudic-type vellum has relatively static values in the region from 43% to 11% RH, with a reduction in the loads-to-break mean only upon There is no significant change in the percent strain-to-break at different relative humidities for talmudic-type parchment. However, while the values for both the modern and medieval types remain static from 60% to 22% RH, there is a clear reduction in percent strain-to-break upon reducing the RH below 22% to 11%. The energy-to-break is calculated from the area under the stress-strain curves. Because the energy required to fracture a sample reflects changes in both the ability to elongate and also to bear a load, this quantity is most representative of the tendency of parchment to fracture at a certain level of relative humidity. However, this quantity also has a wider spread in the standard error because both the uncertainty in the strain-to-break and load-to-break are represented. For the vellum type designated modern, decreasing the relative humidity from 60% to 11% does not result in a mean value outside the uncertainty (standard error) of the values at 60%. For the medieval-type parchment, there is a clear reduction in the mean energy-to-break to half (50%) the original value; the energy-to-break of the talmudic-type parchment is also reduced at lower relative humidities, but to a lesser extent than in the medieval-type.” Does the effect of lowering the relative humidity increase the “brittleness” of newly manufactured vellum? To answer this question, the difference between “brittleness” and “stiffness” should be defined. A “stiffer” material has a higher value for the initial modulus (an indication of inelastic deformation), and therefore the vellum prepared by the modern method became stiffer with a decrease in humidity. “Brittleness,” however, is a reduction in the ability to elongate before breaking. Therefore both the medieval-type and modern-type vellum can be considered more brittle at lower relative humidity levels. These results pertain to two questions:
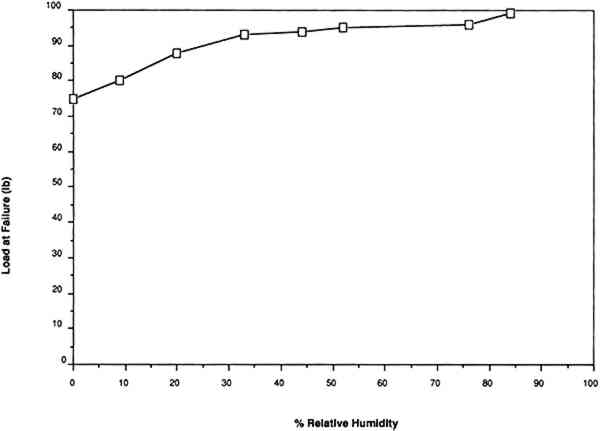
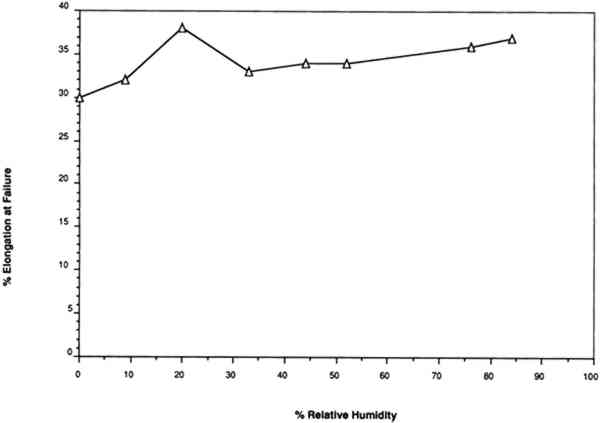
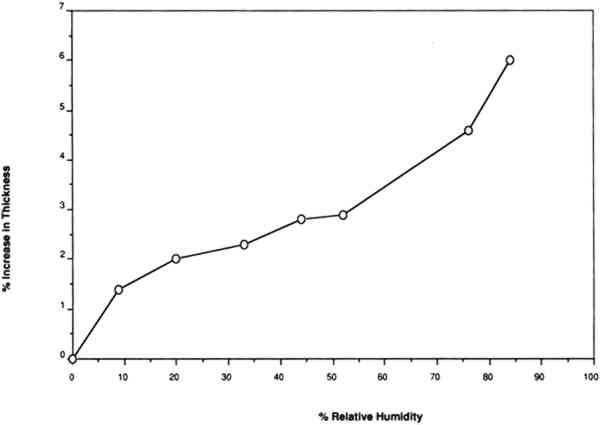
For example, Werner (1968, 286) states that “parchment documents … kept under conditions that are too dry, say at 45 percent relative humidity or lower … tend to cockle and to become rather rigid.”Wilson (1986), in reviewing storage conditions for leather in archives and libraries, considered the results of testing the tensile properties and dimensional changes of vegetable-tanned leather by Evans and Critchfield (1933), reproduced in figures 10 through 12. He concluded that the changes were not large enough to preclude the storage of vegetable-tanned leather at any of these relative humidities on the basis of these data alone. The same general conclusions can be reached for the results of tensile testing on vellum presented here, except for the fact that at 11% RH a notable reduction is evident in some individual properties of specific vellum types: the load-to-break of the medieval-type vellum; the strain-to-break of the medieval-type and modern-type designated vellum; and the energy-to-break of the vellum designated talmudic.
Several effects may account for observations other than those presented here that some parchment becomes brittle below 43% RH. As originally produced, skin artifacts should vary in tensile properties for a variety of reasons including the age at which the animal was slaughtered, the species of the animal, the health of the 4.2 RESULTS OF TESTING RESTRAINED SAMPLESThe same relative behavior was observed for all three types of vellum when restrained at a fixed gauge length and the relative humidity was lowered. As the humidity was lowered from 60% to 22%, relatively little force developed in a restrained sample. However, as the water content was decreased below that contained in vellum equilibrated at 22% RH, there was a significantly large increase in the force (fig. 13). These results clearly indicate that around 25% is the lowest level that can be tolerated without inducing large forces in the vellum.
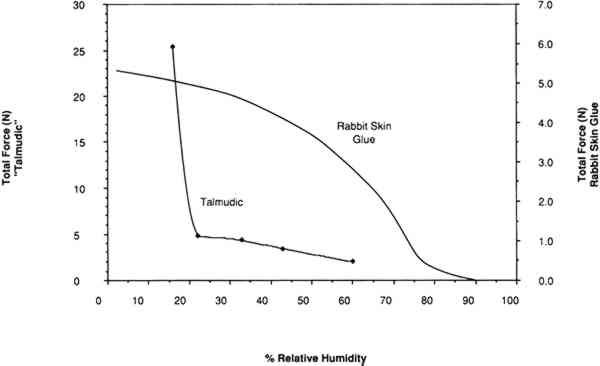
The last result may be explained in reference to the four regions of water sorption associated with the collagen molecule. Below 25% RH, water is removed from the tropocollagen structure, causing an unstable chemical state and, as indicated by the forces developing upon shrinkage, an undesirable mechanical state. A comparison of the force developing as the relative humidity is lowered in a restrained sample of vellum (with a high portion of intact collagen) with the force developing in a sample of cast rabbit skin glue (a highly gelatinized material) is shown in figure 14. A completely different profile, noticeably lacking a large increase in stress below 22%, results in the plot of force development versus relative humidity in the case of rabbit skin glue, wherein little intact tropocollagen is present.
4.3 IMPLICATIONS FOR STORAGE CONDITIONSAs has been shown, a minimum level of relative humidity should be maintained; storage of a parchment below 25% RH is not indicated. Above this relative humidity all strongly water sorbing groups in collagen should be saturated. A similar position was taken by the National Bureau of Standards when the display and storage conditions for the Charters of Freedom of the United States (Declaration of Independence and the Constitution) were defined in 1951 (NBS 1951). These parchment documents are stored under an inert atmosphere of helium humidified to 25% relative humidity. The reasoning of the NBS was based on two sources:
The Charters of Freedom were examined by a panel of scientists and conservators in 1982 without removal from the case (Calmes 1985). No evidence of deterioration beyond that observed Several issues can be raised about the advisability of the long-term storage or display of parchment below the current recommendations for relative humidity, which are usually 50%.
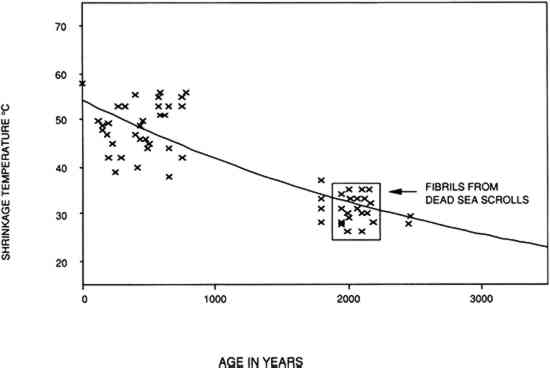
However, there are also several issues that should be raised about the advisability of a 50% RH level for the display and storage of ancient and culturally important parchment documents. The Dead Sea Scrolls are an example of parchment documents whose condition (present state of deterioration) demands further consideration. The Dead Sea Scrolls are a collection of more than 500 parchment documents, many of which are incomplete. The first documents were found in Jordan in 1947. Their manufacture has been attributed to the Quran community (a Jewish sect) and roughly dated between 200 B.C. and 100 A.D. The technology used in their manufacture differs from other parchment manuscripts in that lime was probably not used in the dehairing bath and in the presence of surface tannage (Poole and Reed 1962). In attempting to date the Scrolls, Burton et al. (1959) compared the shrinkage temperature of collagen fibers in the scroll fragments to the shrinkage temperature of samples from parchment or raw hide of known origin (between 1000 B.C. and 1000 A.D.). They reasoned that any degenerative changes in the collagen fibers would be due to the passage of time. The results, shown in figure 15, show that the shrinkage temperature of collagen from the Scrolls, like other older collagen, is low (between 22�C and 35�C) and consistent with the probable time of origin.
Other studies have shown that much of the collagen is not intact. Weiner et al. (1980) examined small pieces of scroll material and random, unwritten fragments to determine the collagen to gelatin ratio using x-ray diffraction and amino acid racemization analyses. By their x-ray diffraction method, they determined the collagen to gelatin indices (C:G) of modern rattail collagen to be 10:2, and the C:G of gelatinized rattail collagen to gelatin to be 0:7. C:G indices of modern parchment samples were 9:9, 9:8, and 12:5. The C:G indices of 34 samples from scrolls or fragments ranged from Samples of scroll fragments were recently analyzed at the Getty Conservation Institute (Derrick 1992) by Fourier transform infrared spectroscopy (FTIR) using both a surface technique (attenuated total reflection) and an FTIR microscope to scan cross sections. This method can detect increased denaturation by a shifting of an absorption band to a lower frequency. The amide II band shifts from 1550 to 1530 cm-1 when the collagen helix is converted to gelatin (Brodksy-Doyle et al. 1975; Susi et al. 1971). Differences in chemical composition resulting from hydrolysis or oxidation can be detected by spectral comparison of modern parchment samples and samples from the scrolls. Analysis indicated evidence of denaturation, hydrolysis, and oxidation that were associated to a greater extent with both brittle areas and also darker, discolored areas. Further analysis included amino acid analysis of modern parchment and scroll parchment by High Performance Liquid Chromatography. Modern parchment was 90% or more extractable by weight, when extracted for collagen, in the preparatory acid hydrolysis prior to amino acid analysis. In contrast, scrolls fragments were less than 70% extractable by weight, indicating extensive oxidative modification of amino acids may have occurred. The Dead Sea Scrolls, then, exhibit a state of deterioration consistent with their age. The extent of degradation is varied but includes evidence of hydrolysis and oxidation in addition to denaturation. Problems that exist with a 50% recommended relative humidity for parchment documents are:
The Dead Sea Scrolls are of particular interest and cultural importance, being among the earliest The above considerations indicate that the practice of humidifying brittle historical parchment at 100% RH to relax the material may be questionable. Exposure to a high relative humidity may have the transitory, beneficial effect of relaxing the parchment to allow unrolling or other manipulations. However, the chemical state of the material, both immediately after relaxation and in the future, needs to be more fully determined regarding possible adverse affects. 5 CONCLUSIONSThis study has sought to determine the optimum relative humidity for objects containing collagen as a principal component. Decreasing the water content reduces both the possibility of biodeterioration and the probability of future environmentally induced chemical modifications of collagen. A lower limit has been discussed for collagen; storage or display below around 25% RH is not indicated. Because of possible cycling effects of � 5%, a slightly higher value, 30% RH, is suggested as the optimum condition for an object for which the long-term preservation of the intact collagen is of greatest concern. However, there are other considerations, particularly in regard to the degree to which a skin object must be manipulated or in determining the possibility of the loss of inks or colorants. In this regard, determining the optimum relative humidity for remains derived from skin has some parallel in the history of conservation to determining safe levels of illumination. When determining the optimum light levels for the display of light-sensitive objects, the illumination recommended is the lowest that will allow the required visibility. In the case of remains derived from skin, the optimum relative humidity is the lowest amount of atmospheric moisture (above 25% RH) that will allow for mechanical requirements, the consideration of other composite elements, and the aesthetic requirements. Previous discussions of optimum relative humidity levels for parchment that have recommended 50% RH or higher have focused primarily upon the pliability and other physical properties of parchment. The work just reported has shown that for organic materials, such as proteins, a knowledge of the chemical changes that occur over time may be as important as a knowledge of the physical properties in determining the most reasonable display and storage conditions. It can be stated that the conditions for maintenance of collagen containing objects should be geared either for the intent of its exhibition or use (long-term display or short-term handling), keeping in mind that relative humidities below 25% are incompatible with long-term maintenance, as are relative humidities above 40%, which increase hydrogen bond breakage, gelatinization, and biological growth. ACKNOWLEDGEMENTSThe contents of this paper have also been published in the AIC Book and Paper Group Annual REFERENCESASTM. 1984. Standard test method for tensile strength of leather, D 2209-80. In Annual book of ASTM standards. Philadelphia: American Society for Testing and Materials. 15.04:453–55. Bloodworth, J. G., and M. J.Parkinson. 1988. The display of parchment and vellum. Journal of the Society of Archivists9(2):65–58. Bowes, J. H., and A. S.Raistrick. 1964. The action of heat and moisture on leather. V. Chemical changes in collagen and tanned collagen. Journal of American Leather Chemists Association59:201–15. Bowes, J. H., and A. S.Raistrick. 1967. The action of heat and moisture on leather. Part VI: Degradation of the collagen. Journal of American Leather Chemists Association62:240–57. Brodsky-Doyle, B., E. G.Bendit, and E. R.Blout. 1975. Infrared spectroscopy of collagen and collagen-like polypeptides. Biopolymers14:937–57. Bull, H. B.1944. Adsorption of water vapor by proteins. Journal of American Chemical Society66:1499–1507. Burton, D.M.B.E., J. B.Poole, and R.Reed. 1959. A new approach to the dating of the Dead Sea Scrolls. Nature164:533–34. Calmes, A.1985. Charters of Freedom of the United States. Museum146:99–101. Derrick, M.1992. Evaluation of the state of degradation of Dead Sea Scroll samples using FT-IR spectroscopy. In American Institute for Conservation Book and Paper Group Annual. 10:49–65. Dole, M., and A. D.McLaren. 1947. The free energy, heat and entropy of sorption of water vapor by proteins and high polymers. Journal of the American Chemical Society96:651–57. Evans, W. D., and C. L.Critchfield. 1933. The effects of atmospheric moisture on the physical properties of vegetable and chrome tanned calf leathers. Journal of Research of the National Bureau of Standards11:147. HainesB. M.1987. Shrinkage temperature in collagen fibres. Leather Conservation News3(2)1–5. Horie, C. V.1990. Deterioration of skin in museum collections. Polymer Degradation and Stability29:109–33. Kanagy, J. R.1940. Effect of oxygen concentration and moisture on the stability of leather at elevated temperatures. Journal of Research of the National Bureau of Standards25:149. Kanagy, J. R.1947. The adsorption of water vapor by untanned hide and various leathers at 100�F. Journal of American Leather Chemists Association42:98. Kozlov, P. V., and G. I.Burdygina. 1983. The structure and properties of solid gelatin and the principles of their modification. Polymer24:651–66. LCC. 1981. The fiber structure of leather. London: Leather Conservation Center. Mecklenburg, M. F.1988. The effects of atmospheric moisture on the mechanical properties of collagen under equilibrium conditions. AIC preprints, 16th Annual Meeting, American Institute for the Conservation, Washington, D.C. 231–42. NBS. 1951. Preservation of the Declaration of Independence and the Constitution of the United States. NBS circular 505. Washington, D.C.: National Bureau of Standards.
Poole, J. B., and R.Reed. 1962. The preparation of leather and parchment by the Dead Sea Scrolls community. Technology and Culture3(1):1–26. Rebricova, N. L., and N. I.Solovyova. 1987. Electron microscopic and biochemical investigation of parchment. ICOM Committee for Conservation preprints, 8th Triennial Meeting, Sydney1197–1200. Reed, R., 1975. The nature and making of parchment. Leeds, England: Elmete Press. Scott, J., 1986. Molecules that keep you in shape. New Scientist111(1518):49–53. Sobel, H., and E.Hansen. 1989. Environmentally produced changes in historic proteins. A: Collagen. Text of poster presented at the Third Annual Symposium of the Protein Society, Seattle, Wash. Susi, J., J. S.Ard, and R. J.Carroll. 1971. Hydration and denaturation of collagen as observed by infrared spectroscopy. Journal of American Leather Chemists Association66 (11):508–19. Valentin, N., M.Lindstorm, and F.Preusser. 1990. Microbial control by low oxygen and low relative humidity environment. Studies in Conservation35:222–30. Vorst, B., 1986. Parchment making: Ancient and modern. Fine Print12(4):209–11, 220–22. Weiner, S., Z.Kustanovich, E.Gil-Av, and W.Traub. 1980. Dead Sea Scroll parchments: Unfolding of the collagen molecules and racemization of aspartic acid. Nature287:820–24. Werner, A. E., 1968. The conservation of leather, wood, bone and ivory, and archival materials. In The conservation of cultural property with special reference to tropical conditions. Paris: UNESCO. 265–90. Wilson, W. K., 1986. Guidelines for environmental conditions for storage of paper-based nonphotographic records in archives and libraries. (Unpublished typescript). 1401 Kurtz Rd., McLean, Va. 22101. Witnauer, L. P., and W. E.Palm. 1968. Influence of cyclic conditioning on the hydrothermal stability of leather.Journal of American Leather Chemists Association63:333–45. Young, G. S., 1990. Microscopical hydrothermal stability measurements of skin and semi-tanned leather. ICOM Committee for Conservation preprints, 8th Triennial Meeting, Dresden. 19(2):626–31. AUTHOR INFORMATIONERIC F. HANSEN graduated from the University of California at Irvine in 1980 with an M.S. in organic chemistry and joined the Getty Conservation Institute in 1985. In his current position as an associate scientist he is pursuing his interests in the environmentally induced deterioration of synthetic and natural organic materials (including collagen, fibroin and keratin), the conservation of ethnographic and archaeological objects, and the analysis of the effects of treatment parameters on the final physical and optical properties of treated objects. Address: Getty Conservation Institute, 4503 Glencoe Ave., Marina del Rey, Calif. 90292. STEVE N. LEE graduated from University of California, Los Angeles, in 1991 with a B.S. in biology with a molecular, cellular, and developmental emphasis. He was employed as a student assistant at the Getty Conservation Institute for three years. He is now currently attending Dartmouth Medical School and hopes to specialize in cardiology. Address: Dartmouth Medical School, Hanover, N.H. 03755. HARRY SOBEL is an investigator of the biochemical process of in-vivo aging with more than 150 publications mainly concerning the effect of age on collagen and connective tissue. He is currently a research associate in the Isotope Laboratory, Institute of Geophysics and Planterary Physics, University of California, Los Angeles, and for the past four years he has been a consultant to the Getty Conservation Institute on the preservation and deterioration of proteinaceous materials. Recent work has focused on residual proteins in historic bone. His interests include the effect of the environment on proteins under ambient conditions and the analysis of proteins for conservation, art historical, and archaeometric interests. Address: Institute of Geophysics and Planetary Physics Laboratory, University of California, Los Angeles, Calif. 90024
 Section Index Section Index |